Editeurs de sites : faut-il bloquer les crawls des bots IA comme chatGPT, Gemini ou Perplexity ?

L'essor fulgurant de l'intelligence artificielle générative bouleverse les règles du jeu pour les éditeurs de sites web.
Depuis 2024, le trafic automatisé a officiellement dépassé l'activité humaine, atteignant 51 % des flux mondiaux sur Internet.
Face à cette nouvelle donne, de plus en plus de robots d'indexation, appelés "bots IA", parcourent le web pour collecter du contenu destiné à l'apprentissage automatique et à l'entraînement des LLM (Large Language Models).
Cette réalité soulève une question existentielle pour les créateurs de contenu : faut-il ériger des barrières pour protéger sa propriété intellectuelle ou, au contraire, collaborer avec ces entreprises d'IA pour capter une nouvelle audience très qualifiée ?
Sommaire
Ce qu'il faut retenir
- Les entreprises d'IA utilisent deux types de bots distincts : ceux dédiés à l'entraînement des modèles (à bloquer) et ceux dédiés à la recherche en temps réel (à autoriser).
- Le fichier robots.txt est un bon point de départ, mais il s'avère souvent insuffisant face aux bots malveillants ou à ceux qui ignorent les directives.
- Une stratégie multicouche est recommandée : combiner robots.txt, règles au niveau du serveur (Apache/Nginx) et pare-feu (ex: Cloudflare).
- Le trafic généré par les outils d'IA (zéro-clic) est en forte hausse, mais les visiteurs qui cliquent sur les sources citées présentent un taux de conversion exceptionnel.
- Natural-net recommande d'autoriser les bots de recherche (OAI-SearchBot, PerplexityBot, Claude-SearchBot) pour optimiser votre stratégie GEO (Generative Engine Optimization).
L'ère du "zéro clic" et l'impact sur le trafic des sites web
Le web est en train de basculer. Les internautes obtiennent désormais des réponses synthétisées directement dans les interfaces d'IA, sans jamais cliquer sur les liens pointant vers les sites d'information. Ce phénomène, exacerbé par des fonctionnalités comme AI Overview de Google, menace directement les revenus et la survie des médias et des éditeurs de contenus. En effet, selon certaines études, les requêtes se terminant sans visite de site atteignent des sommets, privant les éditeurs d'un trafic précieux.
Face à cette captation de valeur, la presse mondiale s'organise. Le New York Times, par exemple, a dénoncé le "vol effronté" de la Silicon Valley, soulignant que les géants de la tech utilisent les œuvres sans consentement clair ni rémunération, ce qui pourrait constituer un véritable problème de droits d'auteur. À l'inverse, des médias comme Le Monde ont fait le choix de la collaboration, signant des accords de licence avec OpenAI ou Perplexity. Louis Dreyfus, président du directoire du Monde, affirme que le taux de conversion d'un utilisateur venant de ChatGPT vers un abonnement payant est 70 fois supérieur à celui de Facebook.
Pour approfondir ce sujet, consultez notre guide SEO pour IA : guide complet du GEO pour optimiser votre visibilité.
Bots d'entraînement vs Bots de recherche : la distinction cruciale
Pour mettre en œuvre une stratégie efficace, il est impératif de comprendre la différence entre un robot d'indexation de moteur de recherche et un robot d'IA. Mieux encore, il faut distinguer les deux rôles principaux des crawlers IA en 2026 :
Les bots d'entraînement (Model Training)
Ces programmes automatisés, véritables aspirateurs numériques, parcourent le web pour visiter des pages web et aspirer massivement des données textuelles, visuelles et structurelles.
Ces informations servent exclusivement à l'entraînement des LLM (Large Language Models), tels que GPT-4 d'OpenAI, Claude 3 d'Anthropic ou les futurs modèles de Google. Dans ce cas de figure précis, votre contenu est ingéré par les systèmes d'IA pour améliorer leurs capacités de compréhension et de génération, mais sans aucune attribution directe ni lien vers votre site.
Pour les éditeurs, le constat est sans appel : ils ne bénéficient d'aucun trafic en retour, ce qui crée un déséquilibre flagrant dans l'échange de valeur. En 2026, on estime que ces robots d'indexation IA et LLM ont quadruplé leur part de trafic en seulement huit mois, représentant désormais une charge non négligeable pour les serveurs sans générer de revenus publicitaires ou de conversions.
C'est pourquoi de nombreux sites choisissent de bloquer ces crawlers IA spécifiques pour préserver leur propriété intellectuelle et éviter que leurs œuvres ne servent à alimenter des modèles d'ia concurrents sans consentement explicite.
Les bots de recherche (Search Indexing / Real-time fetch)
Ces robots interviennent spécifiquement lorsqu'un utilisateur formule une requête conversationnelle auprès d'une interface d'IA générative (comme Perplexity, Claude ou ChatGPT Search). Contrairement aux aspirateurs de données massives, ces agents intelligents effectuent une exploration ciblée pour répondre à une intention précise. Le processus est transparent : l'IA va chercher l'information en temps réel sur vos pages web, synthétiser une réponse pertinente et, point crucial pour votre visibilité, citer systématiquement ses sources avec des liens cliquables vers votre contenu original. Bloquer ces bots revient purement et simplement à se rendre invisible sur ces nouveaux moteurs de recherche et à se priver d'un levier de croissance majeur. Des agents comme OAI-SearchBot ou PerplexityBot sont aujourd'hui les piliers d'un écosystème où la citation directe remplace la simple indexation.
C'est pourquoi, chez Natural-net, en tant qu'experts en stratégie web, SEO et GEO (Generative Engine Optimization), nous préconisons une approche nuancée et pédagogique. Plutôt qu'un blocage binaire et radical, nous recommandons de bloquer les bots d'entraînement (comme GPTBot ou ClaudeBot) pour protéger vos droits d'auteur et votre propriété intellectuelle, tout en autorisant les bots de recherche pour capter un trafic qualifié. Cette distinction est fondamentale : elle vous permet de refuser que vos données servent à l'apprentissage automatique sans compensation, tout en restant éligible aux réponses en temps réel qui génèrent des clics. En 2026, cette gestion fine des agents utilisateurs est la clé pour maintenir une présence forte dans les SERP classiques et les interfaces d'IA, tout en préservant la valeur de vos actifs numériques.
Matrice de décision pour déterminer quels bots IA doivent être bloqués ?
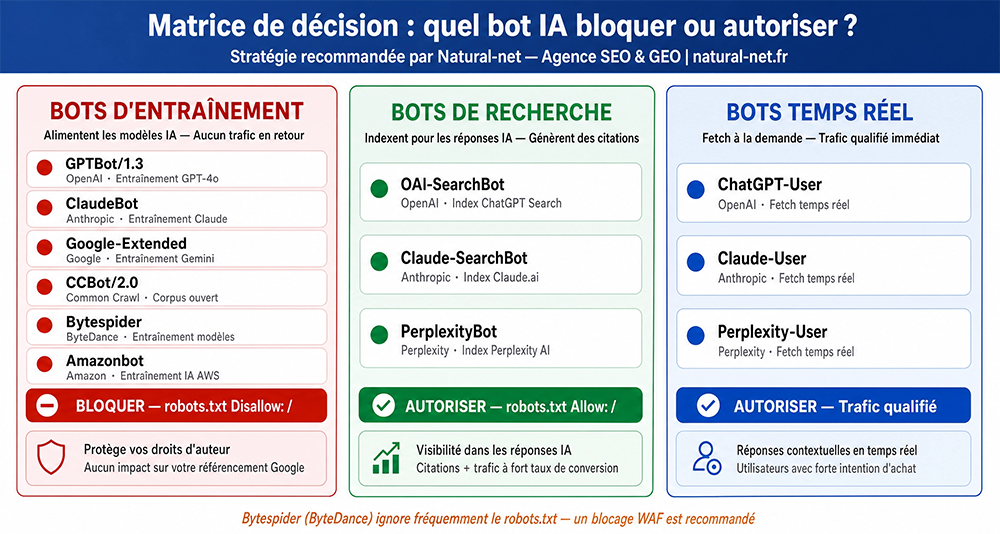
Comment bloquer les bots IA sur un site web ? Les méthodes techniques
La gestion des bots nécessite la mise en place d'une stratégie multicouche. Des simples directives dans le fichier robots.txt aux solutions avancées au niveau du serveur, voici comment procéder.
1. Le fichier robots.txt : un bon point de départ, mais inefficace seul
Le fichier robots.txt est un fichier placé à la racine de votre site web pour indiquer aux bots quelles pages ils peuvent ou ne peuvent pas explorer. Pour vous désinscrire de l'entraînement des modèles d'IA, utilisez le protocole standard. Cependant, son efficacité est variable : certains robots ignorent le fichier robots.txt et contournent les restrictions.
Voici un exemple de configuration optimisée pour 2026 :
# Autoriser les bots de recherche IA (Citations et trafic) User-agent: OAI-SearchBot Allow: / User-agent: ChatGPT-User Allow: / User-agent: PerplexityBot Allow: / User-agent: Claude-SearchBot Allow: / # Bloquer les bots d'entraînement (Protection des données) User-agent: GPTBot Disallow: / User-agent: ClaudeBot Disallow: / User-agent: CCBot Disallow: / User-agent: Google-Extended Disallow: /
Note : Google-Extended est un token de contrôle pour empêcher l'utilisation de vos données pour l'entraînement de Gemini, cela n'affecte pas votre présence dans Google Search.
2. Blocage au niveau du serveur (Apache / Nginx)
Si vous utilisez un serveur Apache ou Nginx, vous pouvez configurer des règles pour bloquer les agents utilisateurs au niveau du serveur. Cela empêche la requête d'aboutir, même si le bot ignore le robots.txt.
Pour Apache (via le fichier .htaccess) :
RewriteEngine On RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|CCBot|Bytespider|Amazonbot) [NC] RewriteRule .* - [F,L]
Pour Nginx :
if ($http_user_agent ~* "(GPTBot|ClaudeBot|CCBot|Bytespider|Amazonbot)") { return 403; }
3. Le blocage par adresses IP et Pare-feu (WAF)
Bien que robots.txt soit un bon point de départ, il ne suffit pas toujours, surtout face à des bots malveillants ou des scrapers agressifs (comme Bytespider de ByteDance). Si cela vous préoccupe, envisagez de combiner robots.txt avec un blocage au niveau du serveur (filtrage d'IP, limitation de débit) ou via un pare-feu applicatif (WAF).
Par exemple, vous pouvez utiliser les adresses IP fournies dans les fichiers officiels d'OpenAI et Perplexity AI pour mettre à jour votre pare-feu. Des solutions comme Cloudflare, disponibles gratuitement sur nos formules d'hébergement web, permettent de configurer une règle de pare-feu basée sur l'agent utilisateur ou le comportement. En seulement six mois, Cloudflare a bloqué pas moins de 400 milliards de requêtes illégitimes liées à l'IA.
Infographie : les 4 niveau de protection des crawls par les bots IA

L'importance du GEO (Generative Engine Optimization)
Si vous souhaitez que le contenu de votre page puisse éventuellement être utilisé par une intelligence artificielle pour formuler des réponses à ses utilisateurs, alors oui, il faut impérativement laisser ces crawlers IA indexer votre site. C'est tout l'enjeu stratégique du GEO (Generative Engine Optimization), une discipline qui s'impose en 2026 comme le complément indispensable du SEO traditionnel.
Contrairement au référencement classique qui vise un positionnement dans une liste de liens, le GEO a pour objectif de transformer votre contenu en une source de vérité que l'IA choisira de citer, de synthétiser et de recommander directement dans son interface conversationnelle.
Le GEO consiste à optimiser vos contenus pour qu'ils soient non seulement compris, mais surtout cités par les IA comme ChatGPT, Gemini ou Perplexity. Pour y parvenir, notre agence préconise une approche rigoureuse : il s'agit de structurer vos données via le balisage Schema.org (JSON-LD) pour faciliter l'extraction sémantique, de répondre de manière factuelle et concise aux intentions de recherche dès les premières lignes (technique de la pyramide inversée), et de maintenir un haut niveau d'expertise, d'expérience, d'autorité et de fiabilité (critères E-E-A-T).
En 2026, l'IA ne se contente plus de mots-clés ; elle évalue la crédibilité globale de la source et la fraîcheur des informations. Une surveillance régulière de vos rapports de performance IA dans la Google Search Console, couplée à une mise à jour agile de votre stratégie de blocage, est essentielle. Les méthodes de collecte des systèmes d'IA et les User-agents évoluent en permanence, et une gestion fine entre bots d'entraînement et bots de recherche est la clé pour rester visible tout en protégeant votre propriété intellectuelle.
Pour aller plus loin, lisez notre Guide du référencement GEO pour les outils d'IA et découvrez comment optimiser votre SEO / GEO pour Google IA Overview.
Trouver le juste équilibre ?
La communauté numérique n'a aucun devoir, ni responsabilité, vis-à-vis de la création des produits des entreprises d'IA. Cependant, se couper totalement de cet écosystème en bloquant tous les crawlers IA est une erreur stratégique. Sans eux, votre contenu ne peut apparaître dans les résultats de recherche conversationnels, et votre site deviendra invisible pour une part grandissante d'internautes.
En mettant en œuvre une stratégie de blocage des crawlers IA fondée sur une approche multicouche (bloquer l'entraînement, autoriser la recherche), vous garantissez la protection de vos actifs numériques tout en assurant une expérience optimale à vos visiteurs humains. N'oubliez pas d'évaluer l'impact sur les vrais utilisateurs : testez vos modifications pour éviter de bloquer accidentellement des visiteurs légitimes.
Foire Aux Questions
Qu'est-ce qu'un bloqueur de bots IA ?
Un bloqueur de bots IA est un ensemble de techniques ou d'outils (comme le fichier robots.txt, des règles de serveur .htaccess, ou un pare-feu comme Cloudflare) permettant d'empêcher les robots d'indexation des entreprises d'intelligence artificielle d'accéder et d'aspirer le contenu d'un site web.
Comment bloquer les bots IA sur un site web ?
Les propriétaires de sites web peuvent mettre en œuvre une stratégie à plusieurs niveaux. Le premier niveau consiste à mettre à jour leur fichier robots.txt afin de restreindre l'accès des robots d'indexation IA (ex: Disallow: / pour GPTBot). Pour plus de sécurité, il est recommandé d'ajouter des règles au niveau du serveur (Apache/Nginx) ou d'utiliser un pare-feu (WAF) pour bloquer les adresses IP ou les User-Agents spécifiques.
Faut-il bloquer les bots IA ?
Il ne faut pas bloquer tous les bots IA de manière indiscriminée. Il est conseillé de bloquer les bots dédiés à l'entraînement des modèles (qui utilisent vos données sans contrepartie) mais d'autoriser les bots de recherche (comme OAI-SearchBot ou PerplexityBot). Sans ces "Bots Amicaux", votre contenu ne peut apparaître dans les réponses des IA, et votre site deviendra invisible en ligne pour ces utilisateurs.
Sources et ressources
- MNTD.fr — "Médias : à l'ère de l'internet du zéro clic, faut-il bloquer ou collaborer avec les entreprises d'IA ?" https://www.mntd.fr/medias-a-lere-de-linternet-du-zero-clic-faut-il-bloquer-ou-collaborer-avec-les-entreprises-dia/
- Cloudflare Blog — "L'indexation avant la chute… des renvois : comprendre l'incidence de l'IA sur les fournisseurs de contenu" https://blog.cloudflare.com/fr-fr/ai-search-crawl-refer-ratio-on-radar/
- Digital Applied — "AI Crawler Access Control: The 2026 Decision Matrix" https://www.digitalapplied.com/blog/ai-crawler-access-control-2026-robots-llms-txt-decision-matrix


